
When it comes to solving a problem, the basic recovery steps are the same, whether you have a smoke alarm chirping it’s need for a new battery, or a network device in a negative state.

UNKNOWN – IDENTIFICATION
Of course, if you don’t know you have a problem, you aren’t going to be trying to solve it. In our example, the smoke alarm begins sending out an short high tone that repeats every few minutes when the battery approaches a critical level. The first time you hear one of these chirps, you might not even think about it. After it’s happened few more times, it gets your attention.
In traditional network problem solving, it’s similar. A device might go down just after being polled over the network by NOC-based software. A few minutes later, the problem is detected for the first time. Most systems are set up to verify this data over the next couple polling cycles before the issue is escalated to a human some 5-, 10-, 15-minutes or more later. The ever-important (and possibly expensive) SLA timer starts here once the problem has been acknowledged. The clock is running. Tick tick.
ISOLATION
If your house is up to code, you probably have numerous smoke alarms. Finding out exactly which one is chirping isn’t always easy and often involves walking around, head cocked to the side like a curious dog, and waiting for the next chirp to try to lock on the source.
Isolating exactly where the problem is in a network can also be difficult. Run book procedures help admins eliminate the most likely causes first and often include a healthy level of initial finger pointing (“surely the problem isn’t with our equipment – it must be the service provider”). These procedures take time, and unlike the smoke alarm that probably has ample warning time built in, with the network, things are dead. This can mean downtime, loss of revenue, and unhappy customers. Tick tick tick.
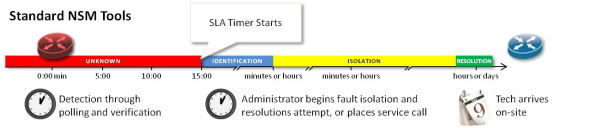
RESOLUTION
To close out the analogy, once the failing smoke detector has been isolated, it’s just a matter of changing out the battery without falling off of the ladder.
For the network, the second half of the job is just beginning. Administrators have to gain access to remote devices through a terminal server (if available) and continue troubleshooting from step 1. If they can’t access the device remotely, they might try to recruit local help to give them basic information (is the green light on?) or take basic actions (hit the reset button on the big gray device with all the wires). If this isn’t an option, it’s time to get in the car or put in a service call. Tick tick tick tick. Time drags on, costs increase.
So what’s the shortcut?
Automation, of course. To tackle this problem with something smarter and faster. Uplogix puts an intelligent appliance in the rack with your network gear and connects over a console port. This means Uplogix isn’t dependent on the network to monitor network devices. Plus, the polling interval can be much more frequent, speeding problem identification.
The individual connections to devices over the console port gives Uplogix a very granular view of the components of the network. Rules can be configured to allow for verification of an issue without adding much time.
Finally, Uplogix can take action and automate most Level 1 and Level 2 run book procedures, which account for the majority of the solutions to network device problems.
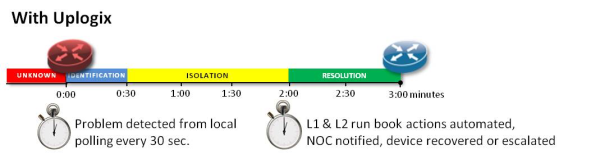
All of this in just minutes instead of the hours or even days of standard network management. Plus, there are other features like integrated out-of-band functionality that means your existing NOC-based tools will continue to receive status information, and admins have the option to connect directly to devices through the Uplogix appliance.
Take advantage of the shortcuts and you’ll have more time for the tough stuff – like finding that darn chirping smoke detector.




